FitVid: Responsive and Flexible Video Content Adaptation




Abstract
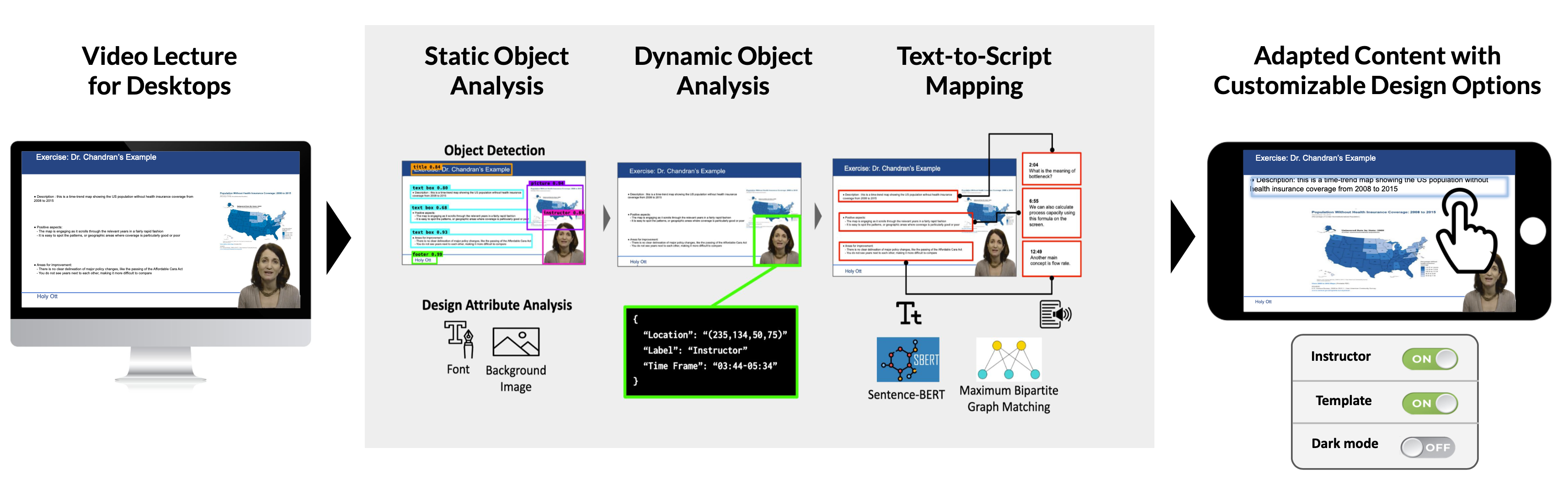
Mobile video-based learning attracts many learners with its mobility and ease of access. However, most lectures are designed for desktops. Our formative study reveals mobile learners’ two major needs: more readable content and customizable video design. To support mobile-optimized learning, we present FitVid, a system that provides responsive and customizable video content. Our system consists of (1) an adaptation pipeline that reverse-engineers pixels to retrieve design elements (e.g., text, images) from videos, leveraging deep learning with a custom dataset, which powers (2) a UI that enables resizing, repositioning, and toggling in-video elements. The content adaptation improves the guideline compliance rate by 24% and 8% for word count and font size. The content evaluation study (n=198) shows that the adaptation signifcantly increases readability and user satisfaction. The user study (n=31) indicates that FitVid signifcantly improves learning experience, interactivity, and concentration. We discuss design implications for responsive and customizable video adaptation.
Video Presentation
Video Interface

▲ Examples of adapted content. (a) Resized fonts and reduced text, (b) Changed column layout, (c) Adjusted image and text at compromise point, (d) Increased color contrast, (e) Changed typeface. The representative failure cases are: (f) overlap-pings due to errors from the object detection stage and (g) incomplete text resizing due to its comparative size with titles © Holly Ott, Aruna Chandran, Charlie Nuttelman, Google Career Certifcates, Philip John Currie, Jim Sullivan
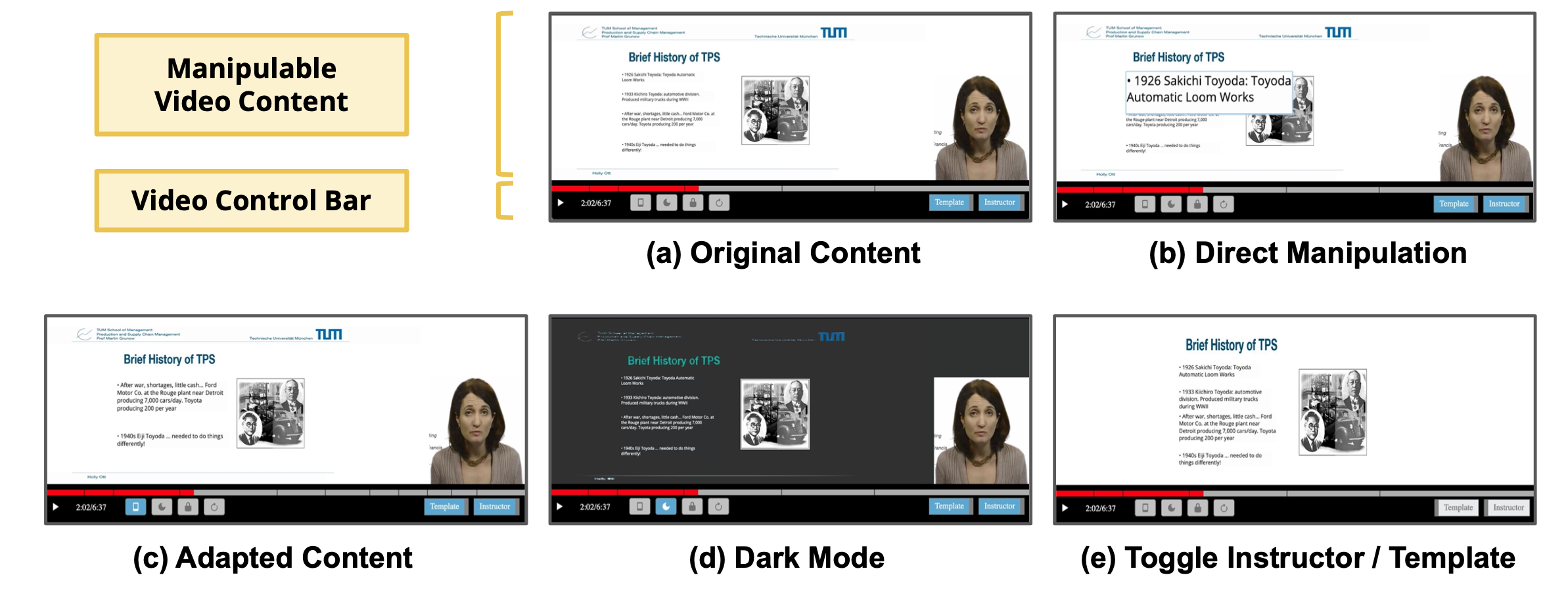
▲ A learner can resize, reposition, and toggle various in-video elements using FitVid's video UI. (a) Original Content: original content without adaptation is displayed to the learner by default, (b) Direct Manipulation: the learner can resize and reposition design elements (e.g., text boxes, images, and talking-head instructors) using touch and drag interactions, (c) Adapted Content: the learner can view the adapted content obtained from the automated pipeline (e.g., size and amount of text are adjusted in the fgure), (d) Dark Mode: the learner can choose the dark background and bright text of video content, (e) Toggle Instructor and Template: the learner can turn on and of the talking-head instructor view and the slide template (e.g., university logos in headers or footers). © Holly Ott
Technical Pipeline
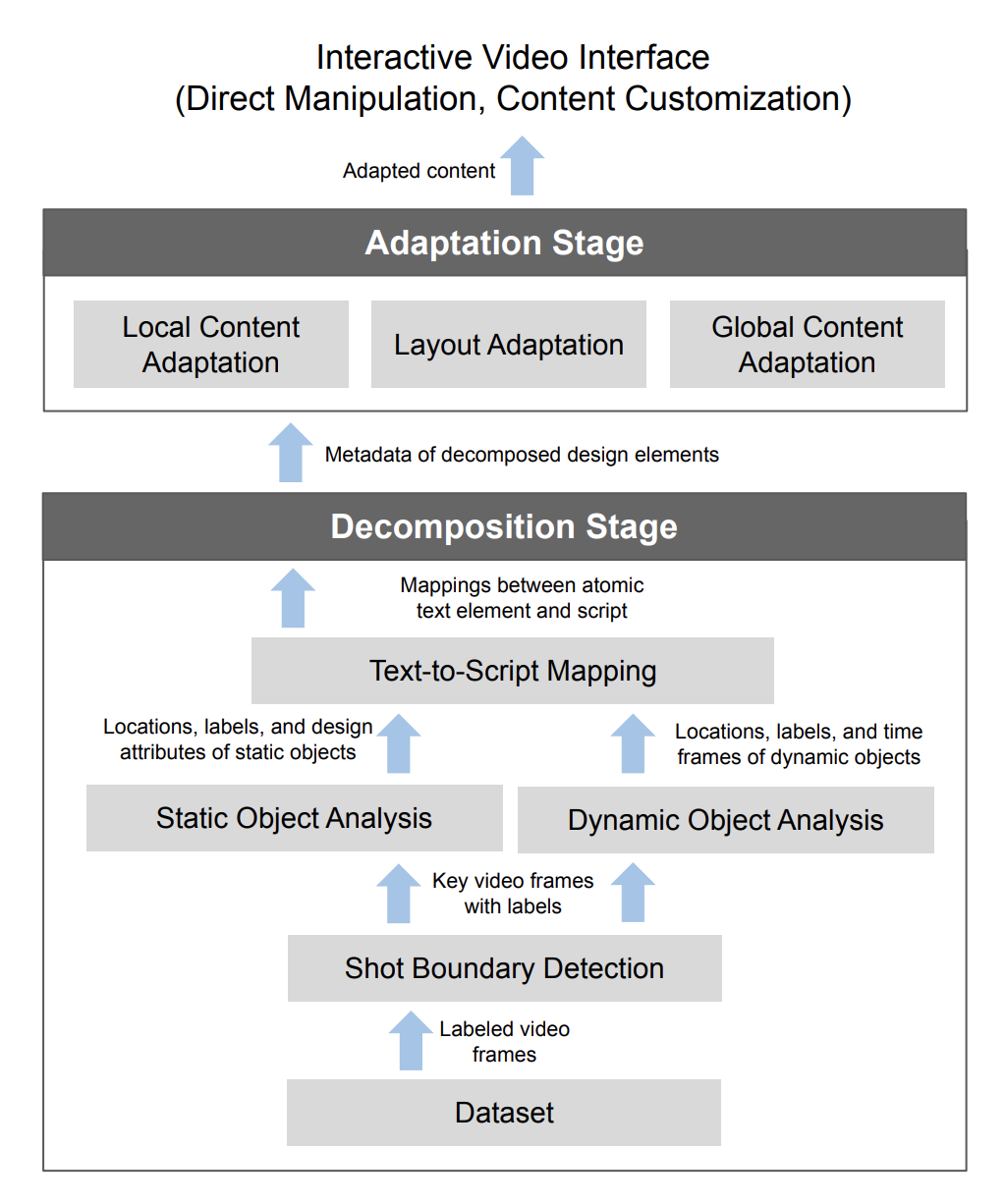
▲ A computational pipeline of FitVid consists of two main stages, decomposition and adaptation. The decomposition stage extracts metadata of in-video elements used for adaptation. The adaptation stage generates and renders adapted content for mobile screens.
Open Dataset and Object Detection Model
Dataset for Lecture Design Elements:
Repository
Lecture Design Object Detection:
Repository
Publication (CHI 2022)
Paper Link:
ACM DL
Paper File:
PDF
@inproceedings{kim2022fitvid,
title={FitVid: Responsive and Flexible Video Content Adaptation},
author={Kim, Jeongyeon and Choi, Yubin and Kahng, Minsuk and Kim, Juho},
booktitle={CHI Conference on Human Factors in Computing Systems},
pages={1--16},
year={2022}
}